Note
Click here to download the full example code
Use Audio to Align Video Data¶
In this example, we use pd-parser to find audio events using the same
algorithm for matching with time-stamps and rejecting misaligned
audio, but applied using the onset of an audio deflection instead of detecting
photodiode events based on their square wave shape.
# Authors: Alex Rockhill <aprockhill@mailbox.org>
#
# License: BSD (3-clause)
Load in a video with audio
In this example, we’ll use audio and instead of aligning electrophysiology data, we’ll align a video. This example data is from a task where movements are played on a monitor for the participant to mirror and the video recording is synchronized by playing a pre-recorded clap. This clap sound, or a similar sound, is recommended for synchronizing audio because the onset is clear and allows good precision in synchronizing events.
Note that the commands that require ffmpeg are pre-computed and commented
out because ffmpeg must be installed to use them and it is not required by
pd-parser.
import os
import os.path as op
import numpy as np
from scipy.io import wavfile
from subprocess import call
# from subprocess import run, PIPE, STDOUT
# import datetime
import mne
from mne.utils import _TempDir
import pd_parser
# get the data
out_dir = _TempDir()
call(['curl -L https://raw.githubusercontent.com/alexrockhill/pd-parser/'
'master/pd_parser/tests/data/test_video.mp4 '
'-o ' + op.join(out_dir, 'test_video.mp4')], shell=True, env=os.environ)
call(['curl -L https://raw.githubusercontent.com/alexrockhill/pd-parser/'
'master/pd_parser/tests/data/test_video.wav '
'-o ' + op.join(out_dir, 'test_video.wav')], shell=True, env=os.environ)
call(['curl -L https://raw.githubusercontent.com/alexrockhill/pd-parser/'
'master/pd_parser/tests/data/test_video_beh.tsv '
'-o ' + op.join(out_dir, 'test_video_beh.tsv')],
shell=True, env=os.environ)
# navigate to the example video
video_fname = op.join(out_dir, 'test_video.mp4')
audio_fname = video_fname.replace('mp4', 'wav') # pre-computed
# extract audio (requires ffmpeg)
# run(['ffmpeg', '-i', video_fname, audio_fname])
fs, data = wavfile.read(audio_fname)
data = data.mean(axis=1) # stereo audio but only need one source
info = mne.create_info(['audio'], fs, ['stim'])
raw = mne.io.RawArray(data[np.newaxis], info)
# find audio-visual time offset
offset = 0 # pre-computed value for this video
'''
result = run(['ffprobe', '-show_entries', 'stream=codec_type,start_time',
'-v', '0', '-of', 'compact=p=1:nk=0', video_fname],
stdout=PIPE, stderr=STDOUT)
output = result.stdout.decode('utf-8').split('\n')
offset = float(output[0].strip('stream|codec_type=video|start_time')) - \
float(output[1].strip('stream|codec_type=audio|start_time'))
'''
# save to disk as required by ``pd-parser``, raw needs a filename
fname = op.join(out_dir, 'sub-1_task-mytask_raw.fif')
raw.save(fname)
# navigate to corresponding behavior
behf = op.join(out_dir, 'test_video_beh.tsv')
Out:
Creating RawArray with float64 data, n_channels=1, n_times=16464896
Range : 0 ... 16464895 = 0.000 ... 343.019 secs
Ready.
Writing /var/folders/s4/y1vlkn8d70jfw7s8s03m9p540000gn/T/tmp_mne_tempdir_ran50pv8/sub-1_task-mytask_raw.fif
Closing /var/folders/s4/y1vlkn8d70jfw7s8s03m9p540000gn/T/tmp_mne_tempdir_ran50pv8/sub-1_task-mytask_raw.fif
[done]
Run the parser
Now we’ll call the main function to automatically parse the audio events.
annot, samples = pd_parser.parse_audio(fname, beh=behf,
beh_key='tone_onset_time',
audio_ch_names=['audio'], zscore=10)
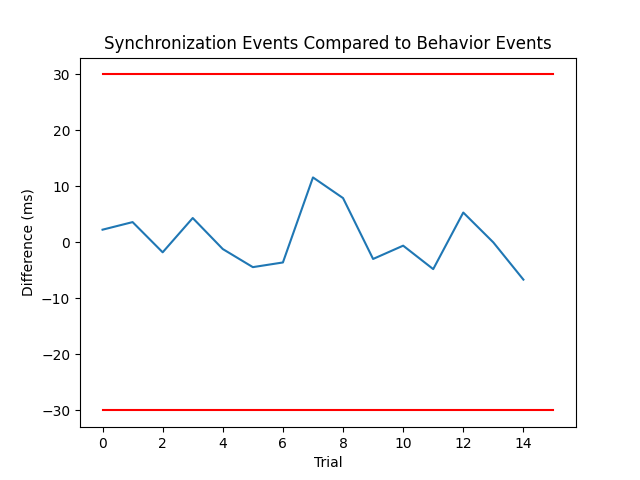
Out:
Reading in /var/folders/s4/y1vlkn8d70jfw7s8s03m9p540000gn/T/tmp_mne_tempdir_ran50pv8/sub-1_task-mytask_raw.fif
Opening raw data file /var/folders/s4/y1vlkn8d70jfw7s8s03m9p540000gn/T/tmp_mne_tempdir_ran50pv8/sub-1_task-mytask_raw.fif...
Isotrak not found
Range : 0 ... 16464895 = 0.000 ... 343.019 secs
Ready.
Reading 0 ... 16464895 = 0.000 ... 343.019 secs...
Finding points where the audio is above `zscore` threshold...
17 audio candidate events found
Checking best alignments
0%| | 0/15 [00:00<?, ?it/s]
53%|#####3 | 8/15 [00:00<00:00, 76.93it/s]
100%|##########| 15/15 [00:00<00:00, 82.61it/s]
Best alignment is with the first behavioral event shifted 0.01 s relative to the first synchronization event and has errors: min -6.65 ms, q1 -3.27 ms, med -0.58 ms, q3 3.99 ms, max 11.60 ms, 0 missed events
Excluding events that have zero close synchronization events or more than one synchronization event within `max_len` time
Load the results
Finally, we’ll load the events and use them to crop the video although it requires ffmpeg so it is commented out.
print('Here are the event times: ', annot.onset)
# Crop the videos with ffmpeg
'''
from pd_parser.parse_pd import _read_tsv
beh = _read_tsv(behf)
for i in range(annot.onset.size): # skip the first video
action_time = (beh['tone_onset'][i] - beh['action_onset'][i]) / 1000
run(['ffmpeg', '-i', f'{video_fname}', '-ss',
str(datetime.timedelta(
seconds=annot.onset[i] - action_time - offset)),
'-to', str(datetime.timedelta(seconds=annot.onset[i] - offset)),
op.join(out_dir, 'movement-{}+action_type-{}.mp4'.format(
beh['movement'][i], beh['action_type'][i]))])
'''
Out:
Here are the event times: [ 19.051125 39.913 61.88575 83.5424375 104.4145625
126.07720833 147.55397917 168.61270833 189.5784375 211.35672917
250.20858333 271.68210417 292.14 313.30533333 333.78097917]
"\nfrom pd_parser.parse_pd import _read_tsv\nbeh = _read_tsv(behf)\nfor i in range(annot.onset.size): # skip the first video\n action_time = (beh['tone_onset'][i] - beh['action_onset'][i]) / 1000\n run(['ffmpeg', '-i', f'{video_fname}', '-ss',\n str(datetime.timedelta(\n seconds=annot.onset[i] - action_time - offset)),\n '-to', str(datetime.timedelta(seconds=annot.onset[i] - offset)),\n op.join(out_dir, 'movement-{}+action_type-{}.mp4'.format(\n beh['movement'][i], beh['action_type'][i]))])\n"
Total running time of the script: ( 0 minutes 24.390 seconds)